
当前,AI大模型赋能千行百业,当AI的触角延伸越广、嵌入越深,一些风险也随之而来。
一、案例展示
一个核心成果的无意识泄露
某航天领域研究团队曾因使用开源AI工具处理卫星轨道计算数据,未关闭“数据上传至模型开发者服务器”功能,导致未公开的轨道参数被境外科研机构获取。调查显示,该工具默认将用户输入数据用于模型迭代训练,且未在用户协议中明确标注,团队因“未履行数据安全审查义务”被通报批评。
于公,大家日常会运用AI处理法律案件、检查工作成果、优化商业模式、财务数据分析。对话中可能会存在整个文件的投喂、输入关键客户信息、透漏具体数字金额的情况。
于私,越来越多的人把AI当作“第二大脑”,做心理咨询、倾诉情绪、梳理人际关系。对话中,难免涉及自己及周边人的隐私信息。
那么,这些数据有没有泄露的风险?
答案是:确实有,而且不小。
二、AI平台处理的基本逻辑?
信息是怎么被泄露的?
大家普遍认为“删掉对话就安全了”。在此我们需要对AI平台的信息处理逻辑有一个通识了解(仅做入门级的原理介绍),几乎所有AI产品都会收集用户输入用于模型训练,这些数据会被平台存储和处理。即上传到开源大模型的任何数据,模型首先会进行存储。
模型会从训练数据中学习并编码信息,即使原始数据被删除,模型参数中仍保留其影响 。即用户删除了前端的对话框,数据也会在平台储存一定时长,并且其影响会嵌入到数百万个相互连接的参数中 ,数据会在模型中被训练与重组(如没有关闭“不允许训练”功能)。即使服务器清除了这些原始数据,其他用户在进行相似问题提问时,也会不经意地对已经删除的数据所留下的模型印记进行激活。当然,这种泄露是间接的,不带关键性标识的。
而直接的信息泄露,是针对被存储的数据,主要通过两条路径:
第一,对开发者开放。 AI工具的开发者可以通过权限看到这些数据。
第二,被黑客攻击。 目前很多AI工具是开源的,黑客会利用大模型本身的漏洞,入侵后台,获取数据。
所以,所有表达的信息,都是有泄露风险的。
三、高频模糊的四大问题
问题一:上传他人的隐私信息或公司内部文件违法吗?
用户处理一批客户合同,借助AI梳理合同要点,提取关键条款。合同里包含客户的姓名、身份证号、联系方式,报价策略。不久,用户收到精准广告推送,内容与正在处理的项目相关。
这意味着什么?用户上传的合同信息已经被AI平台存储、分析,甚至用于模型训练和商业数据挖掘了。该广告是数据被二次利用后的结果。用户在未经客户和公司授权的情况下,将含有隐私和商业秘密的文件交给了第三方平台,这个行为法律上怎么看?
答案是:可能构成侵权,甚至犯罪。
法律风险点:
《民法典》第一千零三十二条:自然人享有隐私权。未经同意上传他人隐私,可能构成侵权。
《反不正当竞争法》第十条:经营者不得实施侵犯商业秘密的行为。
《个人信息保护法》第六十九条:处理个人信息侵害个人信息权益造成损害,个人信息处理者不能证明自己没有过错的,应当承担损害赔偿等侵权责任。
我们来翻译一下:若AI投喂过程中存在商业泄密,那么被侵权人有权以相关法律为依据对你提起诉讼。 如果上传的信息涉及公司财务报表、客户名单、技术代码、商业计划书等商业秘密,且因泄露造成重大损失,在证据链完善的情况下,公司可向泄密者主张赔偿。赔偿金额可能根据商业秘密的价值、研发成本、预期收益等因素综合确定。
问题二:投喂已去掉企业信息的“核心商业模式”安全吗?
在场景应用中,这是一个非常模糊高频的问题,虽可以采取信息“去标识化”,但是商业模式本身往往具有独特性和创新性。如开启训练,你输入的独特商业模式有可能被模型学习并记忆。未来,竞争对手如果向AI提问“请给我一个高效的养老智能用品出海策略”,AI可能会基于你之前投喂的独特模式,生成一份高度相似的商业计划。被竞争对手无意之中唤醒,这在技术上被称为“无意记忆”,对于高度创新的商业模式,是需要考虑的潜在风险。
建议:如果你的商业模式属于核心竞争力,可以关闭“数据用于训练”开关后再提问;也可分多次进行提问,降低被完整记忆的概率。对核心创新点进行模糊化处理,只保留部分框架。
问题三:AI平台输出的信息错误导致损失,平台承担侵权责任吗?
分情况。如果平台已尽到合理注意义务,主观上不存在过错,平台无需担责;反之需要担责。
2025年6月,梁某使用某AI应用程序查询高校报考信息,结果AI提供的高校信息不准确且承诺如生成的内容有误愿意赔偿。梁某遂提起诉讼,要求AI的运营者赔偿9999元,法院驳回了原告的诉讼请求。
AI生成不准确信息本身并不构成侵权,责任认定需考察平台是否违反注意义务。那平台应当履行哪些注意义务?一是对于法律明确禁止生成的有毒、有害、违法信息负严格结果性审查义务;二是需以显著方式向用户提示AI生成内容可能不准确的固有局限性;三是应尽功能可靠性的基本注意义务,采取同行业通行技术措施提高生成内容准确性。本案中,法院审查后认定平台已在应用程序欢迎页、用户协议及交互界面的显著位置,呈现AI生成内容功能局限的提醒标识,且平台已采用检索增强生成等技术提升输出可靠性,认定平台不存在过错,无需担责。
如何降低AI输出错误信息的概率呢?一是优化提问,提问要尽可能具体、清晰,要提供足够多的上下文或背景信息;二是分批输出,AI一次性生成的内容越多,出错的概率就越大,所以要限制它的输出数量;三是交叉验证,可同时向多个AI大模型提出同一问题,交叉对比判断答案可靠性。再次提醒,AI只是辅助工具,我们要保持清醒,不可盲目相信其生成的内容。
问题四:办理案件时,J方是否能调取AI记录
先说答案:是可以的。需在符合法定程序和审批条件的情况下。
根据我国现行法律法规,两高一部”发布的《关于办理刑事案件收集提取和审查判断电子数据若干问题的规定》该规定第三条明确指出:“人民法院、人民检察院和公安机关有权依法向有关单位和个人收集、调取电子数据。有关单位和个人应当如实提供。” 聊天记录在法律上被定义为电子数据,是证据类型的一种。这意味着,一旦办案机关履行了法定程序,网络服务提供者(例如深度求索公司)是有配合义务的。
拿DeepSeek举例,安装平台前《DeepSeek用户协议》第2.5条提到,即使用户注销账户,“平台仍有权按照法律法规的要求,保留该用户的注册数据及以前的行为记录”。这表明,在法律有明确规定时,公司对用户数据的处理可以不受常规删除规则的约束。
四、如何降低日常使用中的泄露风险?
1. 关掉训练开关
大多数主流AI工具都允许用户关闭优化及改进效果的选项。这个操作能有效防止对话内容被永久储存用于训练模型。我们以常见的AI工具举例:豆包APP允许用户在关闭“隐私与权限”里的“帮助模型改进效果”功能;deepseek允许用户关闭“数据管理”里的“数据用于优化体验”功能。
以deepseekAPP为例演示关闭改进功能:
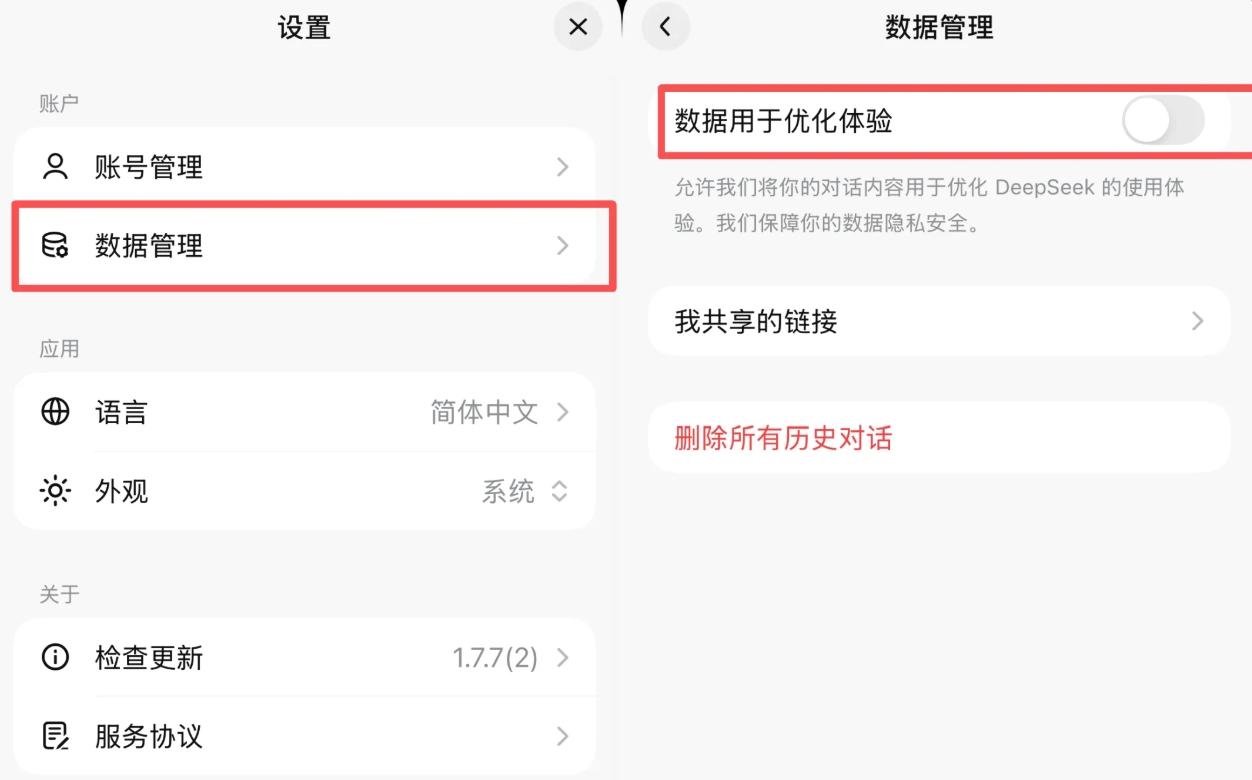
2. 定期清理记录
养成定期删除对话历史的习惯,减少数据被留存的风险。
3. 脱敏投喂文件及删除敏感个人信息
工作文件、报告等,务必先隐藏或替换掉敏感信息后再上传。重新组织问题,去掉所有可识别信息,或改用匿名方式。
高效脱敏的进阶用法:加一道本地脱敏流程,在本地用轻量模型先进行自动脱敏。 比如让模型把文档里的“蓝先生”变成“男士A”,“深圳某科技公司”变成“科技公司X”。 将脱敏结果输入线上 AI 模型,获取你要的分析结果,最后在本地模型中或人工再做“反向替换”,还原成正式版本。
4. 企业用户建议私有化部署
企业在使用开源大模型时,最好采用私有化部署方式——将所有数据保存在本地,避免将内部数据上传到互联网。如果个人部署高配置模型有难度,可以借鉴上述第三点所说的,部署轻量级本地模型,用于敏感信息处理。
花了些时间,把这几个问题彻底理清楚了,这四个问题是被问到最多的,跟大家分享下
